Using Transformers to Analyze Tweets
In this project I use transformer models to analyze tweets

Topic Modeling
Internet forums such as Reddit, X (formerly known as Twitter), Bluesky, and others have exploded in popularity since the rise of social media and widespread adoption of smartphones. These forums serve as important spaces for society to discuss a variety of topics, from sports to politics. What if we wanted to analyze what discussions are happening, and how those discussions change over time?
This is a difficult question, because to be able to do something like that we would have to read through thousands if not hundreds of thousands of tweets and posts. It would be way too expensive to hire enough people to do something like that, and programming a computer to do it instead seems impossible… or is it? Enter transformers, the algorithm behind your favorite AI chatbot ChatGPT. In this post we’ll look into using a fan-favorite transformer model called BERT as part of the BERTopic modeling technique to analyze Trump tweets. This idea came from a class project for my Multivariate Statistical Analysis class in my graduate prgram at BYU, and from my masters project using Large-Language models.
Natural Language Processing
First off, as I like to do in my other posts we’ll talk briefly about the math involved in the algorithm, and motivate it a little bit with a breif history of natural language processing.
Natural language processing (NLP) is a field that focuses on training algorithms to understand human language. This could mean anything from answering questions about a block of text, producing text, translating text, identifying important information such as names and dates in a text, classifying sentiment in text, and much more. NLP is a major field of research today because humans communicate chiefly through natural language. The ability to effectively leverage natural language is the reason for the recent explosion in AI.
Regardless of methodology, the general steps taken to analyze natural language are the same. The goal is to 1) Break the text into meaningful pieces that an algorithm can digest 2) Extract the meaning and information from the text and 3) return the information to the user. Each of these steps have proven to be thorny issues for NLP practitioners and several methods have been developed over the years to address each one. As methodology and computational power have improved, the ability for machines to be trained to understand natural language has skyrocketed.
Getting machines to understand natural language has been an exciting problem from the outset because of the nature of how machines process data. Machines work with and understand numbers, not text. Text data then needs to be transformed into numeric data before it can be fed into a machine. One example of encoding words to numbers is the TF-IDF (Term Frequency - Inverse Document Frequency) matrix, which essentially compares the frequency of words inside a document to the frequency of that word across other documents. Each word is then assigned a numeric score by the document it is in which then allows for analysis.
A more aggressive approach to encoding text data is to simply assign each word an id. That way each word has a unique numeric identifier, numeric so that the computer can perform an analysis and unique so that it can tell words apart. Unfortunately, these identifiers disregard any attempt at also encoding the meaning of the words. As an alternative method, consider a multi-dimensional numeric identifier. A vector with several hundred dimensions can be assigned to each word with each element in the vector encapsulating some idea about the meaning of the word. This is called a vector embedding.

In today’s data pre-processing pipeline, words are broken down into tokens before producing their embeddings. A token can be a whole word or just part of one (prefix, suffix, punctuation mark even). Tokenizing words helps machines understand things such as verb tenses, compound words, and other parts of speech. Once a chunk of text has been tokenized and the machine has the respective embeddings it can then begin analyzing text.
Once you have vector embeddings, the vectors behave much like the words do themselves. In fact, you can even pull certain meanings out of the words such as synonyms, antonyms, and other words associations. “Word math” with vector embeddings is represented in the picture below, where the vector embedding for “queen” has the same relationship with the word “woman” as the embedding for “king” has with “man”. So, if you subtracted the vector for “man” from the vector for “king” and then added the vector for “woman”, you would be left with a vector very similar to the actual embedding for the word “queen”. Amazing!
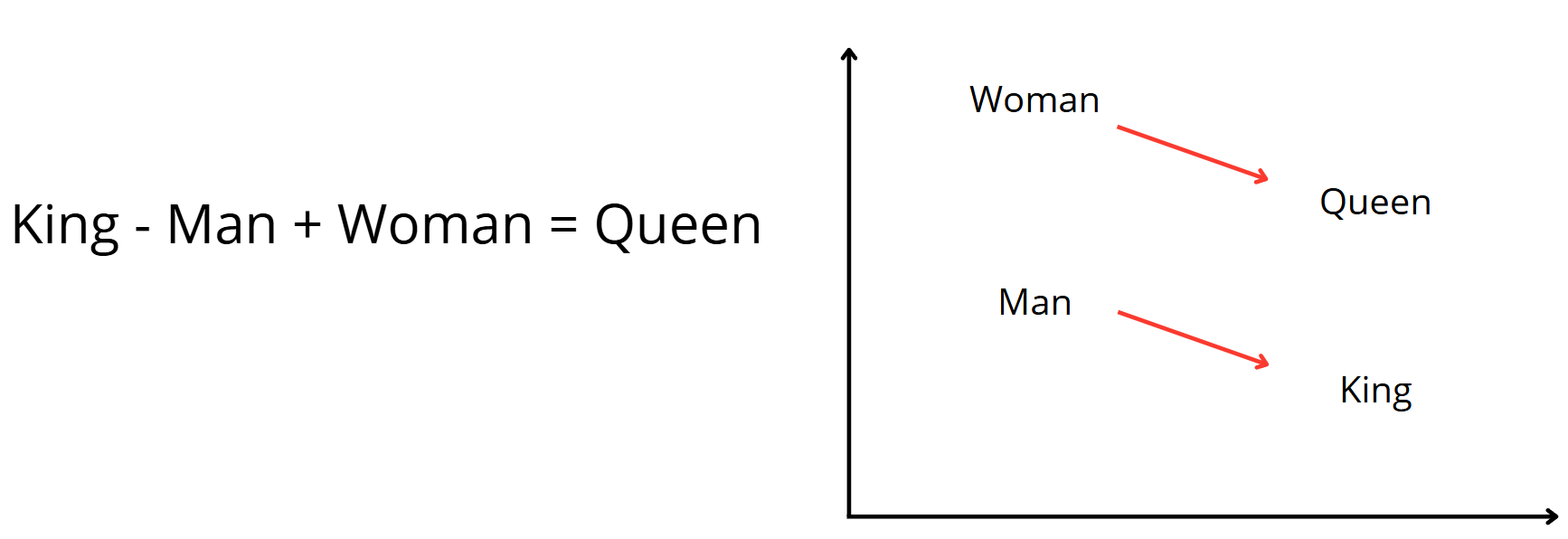
Vector embeddings allow for words and their meaning to be represented numerically. However, vector embeddings alone do not constitute the entire NLP workflow. Modern computational power has enabled NLP practitioners to leverage large machine learning models such as neural networks when analyzing these new embeddings. This has led to a massive leap in the ability of NLP practitioners to analyze text data. I won’t dive in too deep about neural networks, I’ll leave that for when I post the results of my masters project. But suffice it to say as these nueral networks have advanced in both size and architecture they have evolved into what we know today as transformer models, which what models such as ChatGPT are based on. ChatGPT is a decoder-only model, as are most generative models. In my project I used BERT, which is an encoder-only model. Instead of generating text, it produces glorified text embeddings like I talked about above. These embeddings are great for classification tasks, and as it turns out, clustering.
Clustering
So back to the original problem at hand. We want to analyze tweets. For this we will attempt topic modeling, which is a clustering problem by nature. We want to find tweets that talk about the same things, put them together in a group, and find some common themes among those similar tweets. For this project I’ll be analyzing Trump tweets. I got this idea from the original BERTopic paper, which also used their model to analyze Trump tweets and pointed to an easy location to access them called the Trump Twitter Archive. I first filtered out all retweets, which left me with 46,694 tweets between January 1st, 2013 and September 9th, 2020. Now we can get to using BERTopic.
BERTopic
BERTopic is a topic modeling technique that uses a modular design, meaning you can swap in and out different algorithms for each of the steps involved. By default, BERTopic will use sentence-BERT for sentence embeddings (getting a vector embedding for a whole sentence or document rather than for a single token), UMAP for dimension reduction (clustering methods work poorly in high-dimensional space, and BERT produces 768-dimensional embeddings), HDBSCAN for clustering, and a specialized c-TF-IDF algorithm for extracting topic keywords. Put simply, BERTopic clusters the tweets and then finds key words in each of the tweet clusters that make that cluster unique. Because BERTopic is modular, you can instead use your own favorite sentence-embedding model or clustering method, or you can choose to avoid dimension reduction entirely. The authors of the BERTopic paper have released their own Python library and documentation that make getting started really easy, I recommend you check them out.
Results
Along with the algorithm, the BERTopic package also includes neat custom Plotly plots that demonstrate the results. That’s what I use for the plots below. This first plot used HDBSCAN as the clustering method on a subset of the data (5000 randomly selected tweets). HDBSCAN is a unique clustering method in that you do not have to specify beforehand the number of clusters you think there are, it finds the optimal number for you. In this case, HDBSCAN found 72 different topics/clusters.
Also as a note, because there are so many topics the graph can become rather busy. I find that double-clicking on the legend unselects all of the topics, then you can single-click on the topics that you want to display. That does also mean this could be rather difficult on mobile.
The largest cluster is a cluster of just hyperlinks. It looks like it is not uncommon at all for Trump to tweet out links to his followers. The second largest topic is Trump sending out thank yous and encouragment while on the campaign trail. The third most common topic is general thank yous, the fourth looks like they are tweets about entreprenuership, and the fifth looks like it is people tweeting at Trump to run for president. The rest of the tweets capture interesting political topics, everything from tariffs and China to tax cuts. What makes this plot interesting is that it places the clusters of tweets in 2D space based on how similar the topics are. That’s why the topics that are mostly hyperlinks or just the words “thank you” are far apart in space from the other topics.
I also recreated this same graph using two other clustering methods, KMeans and agglomerative clustering using Ward’s linkage. What is interesting to see here is the lines that these clustering methods draw across the tweets, where HDBSCAN does not draw those lines. With clustering and unsupervised learning in general, there is no “correct” answer. The idea is to simply let the model introduce new ideas and identify patterns in the data.
Overall, this project showed how transformer-based models like BERT, combined with clustering techniques, can uncover meaningful structure in large, messy datasets like Twitter. Even without human labeling, these models can find themes ranging from campaign slogans to major political issues.
In the future, I think the next step would be to try topic modeling with a generative model and compare that against BERTopic, or even attempt temporal analysis: how did topics change over time? Did sentiment within topics shift? Investigating these patterns could provide deeper insights into how public conversation and opinion evolve across key political moments.
As transformer models continue to improve, the ability to map and understand digital discourse at scale will only become more powerful — offering new ways to study everything from political communication to cultural trends.
